本文共 1087 字,大约阅读时间需要 3 分钟。
全文检索:
将整个文本进行“分词”处理,在索引库中为分词得到的每一个词都建立索引,和用户搜索的关键词进行匹配。实现快速查找效果。
传统sql语句实现的局限性:
select song_id,song_name,song_singer,song_album
from table_song
where song_name like “%神话%” or song_album like “%神话%” or song_lyric like “%神话%”
效率低,影响性能。
数据库使用索引有无的区别:
i. 不使用索引
从字典中查“王”:从正文的第一页开始,逐页检查,看当前页中是否有“猪”这个字。要是没有再翻下一页。
ii. 使用索引
从字典中查“王”:先根据这个字的拼音或偏旁部首在“检字表”中找到这个字所在的页码,例如是857页,然后直接翻到857页,找到这个字。
全文检索技术:
Lucene和solr
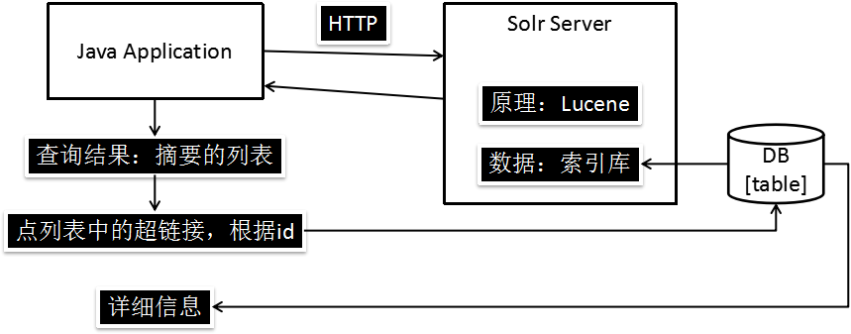
索引库的结构:
索引库中的内容并不是一张完整的数据库表,因为有些内容在查询结果列表中不显示,所以不需要放在索引库中。

字段域的创建:
常用类型:
- IntField
- StringField
- TextField
分词的概念
把一句话/一篇文章拆分成一个一个单个的词,并在内部统计每个词出现的频率,以此为依据进行后续的查询搜索。
Good morning lily
[good]
[morning]
[lily]
我爱炒鸡蛋
[我] [我]
[爱] [爱]
[炒] [炒鸡蛋]
[鸡蛋]
不分词的例子:“地址”字段中的“深圳”数据就不需要分词。不分词的字符串类型就使用StringField,分词的字符串就使用TextField。
建立索引
在索引库内部,将一个具体的索引值和文档中分词的结果关联起来,在搜索时使用索引可以快速定位到对应的词,进而快速定位到词所在的文档。
只有需要和搜索关键词匹配的字段才需要建立索引。
需要建立索引的字段例子:根据“神话”这个关键词搜索“song_name”字段中“神话”这条记录。
不需要建立索引的字段的例子:图片的路径/aaa/bbb/ccc/pic10.png所在的picture_path字段不需要建立索引。
字段的相关属性
-
数据类型:int、double、字符串等等
-
是否分词
- 要分词:包含很多词的一句话
- 不分词:分词之后失去本来的含义
-
是否建立索引
- 要建立索引:用户会根据关键词搜索这个字段
- 不建立索引:用户不会根据关键词搜索这个字段
-
是否存储
-
要存储:在查询结果列表中要显示,或会用到
-
不存储:在查询结果列表中不显示也不会用到
-
转载地址:http://rgwua.baihongyu.com/